
Einleitung
Vorgestern habe ich ein kleines Experiment gestartet. Mein Ziel: Einmal komplett durch den gesamten Entstehungsprozess von einer Datenquelle (zum Beispiel Abrechnungssystem) bis zu einem fertigen Dashboard gehen. Nur ein paar Tools, etwas Grundwissen – und genau den einen Tag, den ich mir dafür reserviert habe.
Knapp 13 Stunden später habe ich zwar mein zeitliches Ziel gerissen und ich war schon in den frühen Morgenstunden des Folgetages,. Aber ich hatte einen funktionierenden Prototypen, ausgehend von einer „gefakte“ Datenbank (eines „gefakten“ Abrechnungssystems) bis zu den Visuals in Power BI (Microsoft) und einem ersten Dashboard. Aber viel wichtiger: eine Lernkurve, die ich in 25 Jahren Berufserfahrung so noch nie erlebt habe.
Hier möchte ich euch auf meinen „process of gaining insights“ mitnehmen!
Warum das Ganze?
In den letzten Jahren habe ich mich immer sehr stark um optimierte Prozesse gekümmert. Sei es beim User-Onboarding auf Plattformen oder beim Gestalten und Umsetzen effizienter interner Prozesse. Erst nur auf dem Papier, zuletzt auch durch Einsatz von Automatisierungs-Tools. Hier habe ich mittlerweile ein wirklich passables Level erreicht, um Business-Prozesse auf die nächste Ebene zu heben.
Das Thema Daten – und zwar im Sinne von Business Intelligence (BI) – habe ich bisher operativ etwas ausgespart. BI ist der technologische Prozess zur Erfassung, Analyse und Präsentation von Geschäftsdaten. Damit legt BI eine wichtige Grundlage für fundierte Entscheidungen und für optimierte Unternehmensleistungen. BI-Tools sind dabei die technischen Werkzeuge, mit denen Rohdaten in verwertbare Erkenntnisse umgewandelt werden. Mit ihrer Hilfe lassen sich Berichte, Visualisierungen und Dashboards erstellen. Die Kernbestandteile und Prozesse sind dabei:
- Datenvisualisierung und Berichterstellung: Präsentation der gewonnenen Erkenntnisse in verständlicher Form durch Dashboards, Berichte und interaktive Grafiken.
- Datenerfassung und -speicherung:Sammeln von Daten aus verschiedenen internen und externen Quellen sowie deren Speicherung in Data Warehouses oder anderen Datenrepositorien.
- Datenanalyse:Nutzung von Methoden und Tools wie Data Mining, Abfragen, statistischer Analyse und maschinellem Lernen, um Muster und Erkenntnisse in den Daten zu finden.
Weil es ein so zentrales Thema für Unternehmen und deren Entscheider ist, wollte ich unbedingt mal den Entwicklungsprozess „End-to-End“ durchlaufen. Ich weiß natürlich, dass für „high-end“ Data Analytics etwas mehr dazugehört als ich das mal eben mit hands-on-Marnier beisteuern kann. Aber viele Unternehmen sind ja auch noch ganz weit weg von „high-end“ und schlagen sich eher mit historischen Reporting-Tools oder Excel bei hohem manuellem Aufwand herum. Und darum wollte ich ein Gefühl entwickeln, wie viel mit heutigen No-Code-Technologien und ein bisschen KI-Magie möglich ist, um auch ohne mehrjähriger BI-Expertise ein neues Level zu erreichen. Denn der Bedarf nach Lösungen, die mit Boardmitteln realisierbar sind, ist hoch!
Der Versuchsaufbau
Fake your SQL Database
BI ohne Daten ist bekanntlich schwer. Für mein Sandkastenspiel war daher wichtig, dass ich irgendeine einigermaßen plausible Datenbank (d.h. mit plausibler Struktur und plausiblen Testdaten) als Basis nutzen kann. Ich bin kein Entwickler und das Aufsetzen einer Datenbank ist für mich kein every day job. Also musste ich mich zwangsläufig damit auseinandersetzen, wie und wo ich zeiteffizient eine SQL-Datenbank aufsetze.
Das war der erste Einsatz für ChatGPT. Dialogisch haben „wir“ uns für Railway als Lösungsalternative entschieden, denn hier lässt sich innerhalb von wenigen Minuten eine MySQL-Datenbank deployen. Der Zugriff erfolgt bei mir dann über MySQL Workbench – quasi als Verwaltungsprogramm, mit dem ich in dieser Datenbank Tabellen inkl. Datenfelder erstellen kann und Daten einpflegen / importieren. Mit beiden Tools hatte ich vorher noch nie gearbeitet. Mein gesamtes Onboarding ist mit Hilfe von ChatGPT und einem kurzen 20min Videotutorial (in portugisischer Sprache 🙂 erfolgt und hat mit damals ein paar Sackgassen unter 1,5 Stunden gedauert. Warum damals? Das habe ich zugegebenermaßen schon für ein anderes Projekt vor ein paar Monaten gemacht. Hier konnte ich also diesmal meine eigene Dokumentation zurückgreifen und war daher in wenigen Minuten startklar!
Datenmodell designen
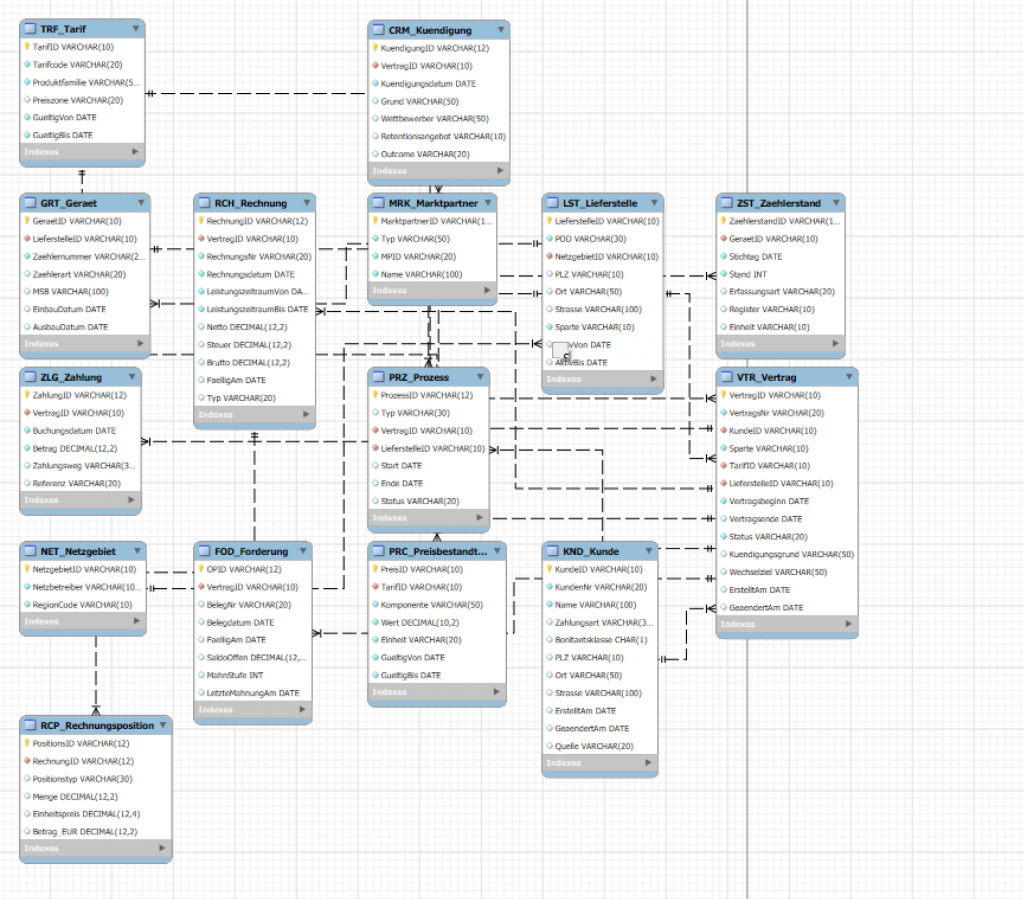
Im nächsten Schritt brauchte ich noch ein Datenmodell. Ein Datenmodell beschreibt, wie Informationen strukturiert und miteinander verknüpft sind – also Tabellen, Attribute und Beziehungen. Dabei wollte ich etwas haben, das sich zumindest einmal grob an der Tabellenstruktur eines energiewirtschaftlichen Abrechnungssystems orientiert. Natürlich nicht mit 200+ Tabellen, aber ca. 15 Tabellen, die auch in einer sinnvollen Beziehung zueinander stehen.
Zweiter Einsatz für ChatGPT. Die KI hat relativ selbstständig das Aufstellen der Tabellen, Beziehungen und Constraints „erarbeitet“. Am Ende stand ein logisches Kernmodell mit „sinnvollen“ Tabellen wie Kunde, Vertrag, Lieferstelle, Gerät, Zählerstand, Tarif, Rechnung, Rechnungsposition, Netzgebiet, Marktpartner, … Zu jeder Tabelle hatte ich relevante Datenfelder sowie eventuelle Relationen zu anderen Tabellen. Zum Beispiel in der Tabelle Gerät (Zähler) gibt es die Felder: ZählerID, LieferstellenID (Relation zu Tabelle Lieferstelle), Zählernummer, Zählerart, Einbaudatum, Ausbaudatum.
Datenmodell implementieren: Tabellen in Datenbank anlegen
Im nächsten Schritt muss die SQL-Datenbank gemäß erarbeitetem Datenmodell aufgesetzt werden. D.h. in der Datenbank werden die Datenstrukturen, also die Tabellen, angelegt. Das erfolgt in DDL (Data Definition Language). Und auch hier bin ich ziemlich blank. Folglich …
Dritter Einsatz des unermüdlichen KI-Buddy, der mir für jede Tabelle die Anweisung für die Erstellung der Tabellen generiert hat. Und zwar in der richtigen Reihenfolge, so dass auch Tabellenrelationen / constraints richtig angelegt werden konnten.
Und so sieht der DDL-Code für die Tabelle „GRT_Geraet“ aus, den ich dann einfach nur nehmen, in die MySQL Workbench kopieren und ausführen lassen musste:
Initialdaten generieren
Um später auch mit einigermaßen plausiblen Daten arbeiten zu können, mussten alle Tabellen mit ausreichend Testdaten befüllt werden. Wenn man sich für 15 Tabellen mit jeweils 5 bis zu 200 Datensätzen alles selbst überlegen muss – viel Spaß. Und wieder war da „jemand“:
ChatGPT hat mir zu dem vorher entwickelten Datenmodell auch direkt die Musterdaten generiert – schön als Exceldatei. Hieraus konnte ich dann schnell csv-Dateien erstellen, die sich dann relativ schnell und einfach in die Datenbank importieren lassen. Wichtig dabei ist die richtige Reihenfolge, damit die oben schon beschriebenen Relationen keinen Fehler auswerfen und der Import nicht erfolgt. Und natürlich: Die von ChatGPT generierte Excel hatte direkt die richtige Reihenfolge, so dass ich Reiter für Reiter den Import anstoßen konnte.
A Star is born
Für BI ist eine saubere Modellstruktur erforderlich, um die Komplexität zu reduzieren und die Performance zu erhöhen. Das Modell bildet dann auch die Grundlage für den nächsten Schritt: „Views generieren“. Hier gibt es verschiedene Schemata, u.a. das Star-Schema. Es heißt so, weil das Modell aussieht wie ein Stern: In der Mitte: Fakten (Messgrößen, z. B. Umsatz, kWh, Zahlungen). Drum herum: Dimensionen (Stammdaten, Kontext, z. B. Kunde, Tarif, Zeit, Region). Jede Dimension hängt direkt an der Faktentabelle → wie Strahlen eines Sterns. Und wieder half mir … – und hat direkt auch ein kleines (nicht ganz so schönes) Schema-Diagramm erstellt.
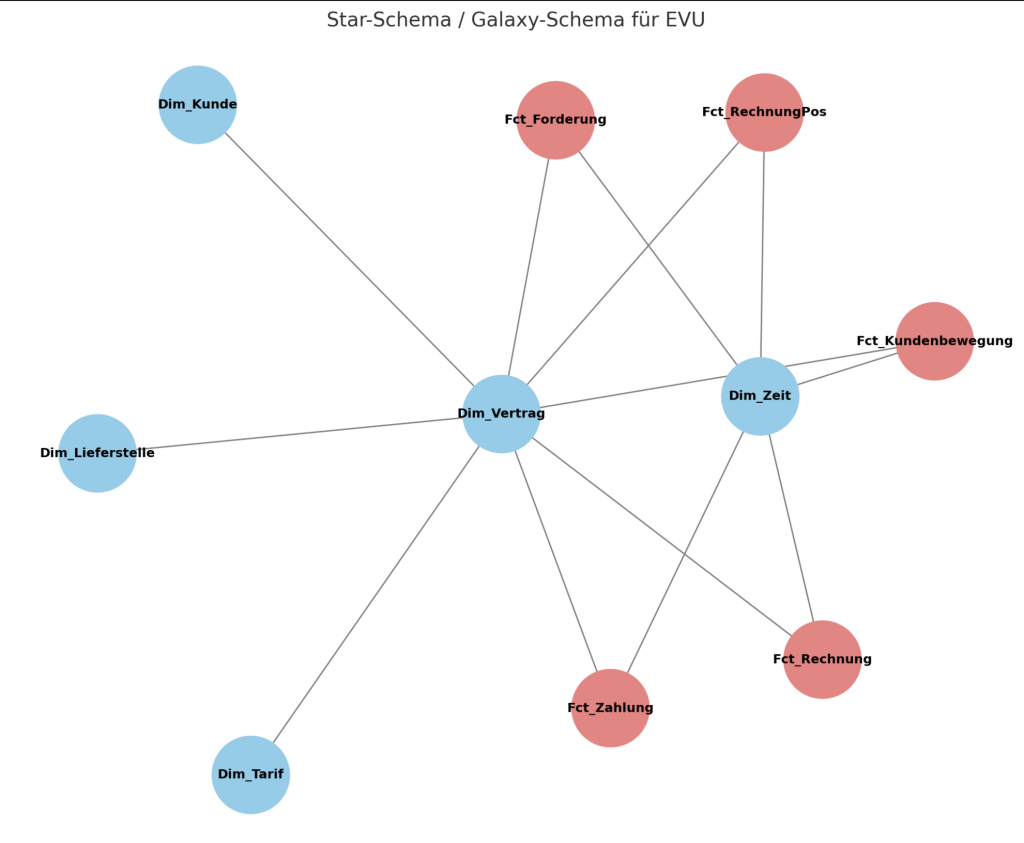
Views generieren
Views sind so etwas wie die Brücke zwischen Datenbank und BI. Views sind „virtuelle Tabellen“, also gespeicherte SQL-Abfragen, die du wie echte Tabellen lesen kannst (SELECT … FROM view). Sie bieten viele Vorteile:
Performance-Steuerung: Du kannst die Views so bauen, dass Power BI wenige und zielgerichtete Daten zieht (Filter/DateKeys/Indizes).
Entkopplung: Du kapselst komplexe Joins/Filter/Spaltenlogik von den Roh-Tabellen. Reports greifen nur auf „kuratiertes“ Schema zu.
Stabilität: Später änderst du die interne Logik (z. B. neue Spalte, geänderter Join), ohne dass sich jede Auswertung ändert.
Sicherheit: Du gibst nur die Views zum Lesen frei (Least Privilege), nicht alle Roh-Tabellen.
Standardisierung: Einheitliche KPI-Grundlagen (kein „jeder baut sich seine eigene Join-Logik“).
Auf Basis des oben entworfenen Schema hat ChatGPT alle SQL-Statements geschrieben mit denen ich die vorgesehenen Views in der Datenbank erzeugen konnte. Gleiches Spiel wie bei der Anlage der Tabellen oben. Nehme den Code, packe ihn in die MySQL Workbench und drücke auf ausführen.
Und hier gab es trotz mehrerer Iterationen ein paar Syntaxfehler, die einen vollständigen Aufbau verhindert haben. An der Stelle bin ich dann zu Claude gewechselt und habe die SQL-Statements dort gedebugged. Und das hat auch prima funktioniert. Kurz Einordnung: Für Coding-Aufgaben nutze ich eh meistens Claude, weil es nach meinem Gefühl und bei meinem sehr begrenzten Coding-Hintergrundwissen, zu besseren Ergebnissen und weniger Iterationen führt. Meine Beobachtung zumindest. In meinem Versuchsaufbau war es aber sinnvoll, die gesamte Iteration mit der KI immer in einem Chatverlauf zu halten. Damit war für ChatGPT laufend der gesamte Kontext klar und daher habe ich auch die kleineren Coding-Probleme gerne in Kauf genommen.

Dashboard-Design
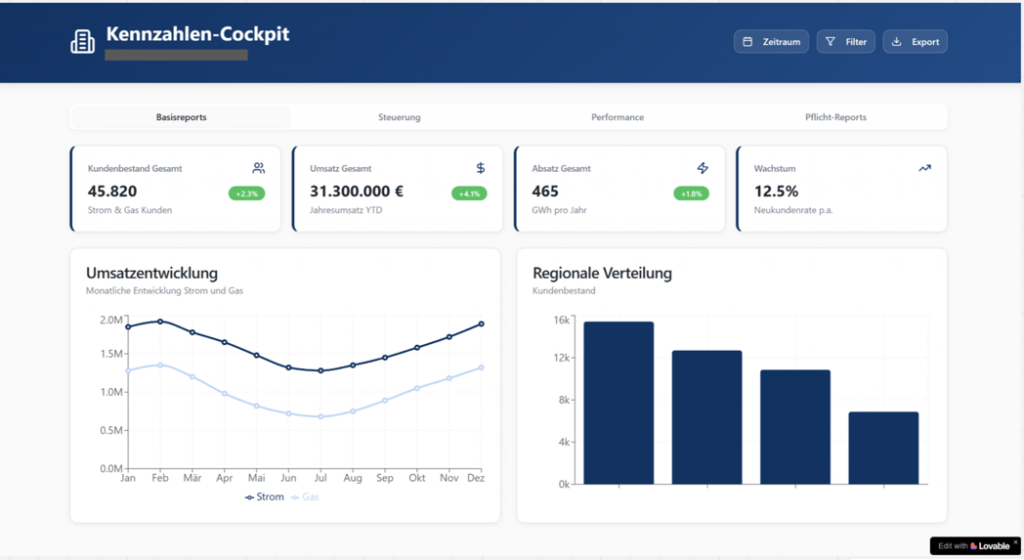
Anschließend ging es um die Frage, wie denn so ein Dashboard aussehen könnte. Hier kam lovable.ai ins Spiel Mit lovable lässt sich auf Basis eines Prompts eine (mehr oder weniger fertige) Applikation, z.B. eine Webpage, erstellen. Der gestufte Prozess war hier: lasse ChatGPT (mit den bereits umfangreichen Hintergrundinformationen zu meinem Projekt) doch direkt den Prompt für lovable.ai schreiben. Ich hatte nur noch ein paar Styling-Informationen mitgeben, den Rest hat dann ChatGPT erledigt.
Den ersten Wurf – ohne Überarbeitung – fand ich schon mal gar nicht so schlecht. Das Ergebnis ist ein Klick-Dummy. In den Folgeschritten muss man sich noch entscheiden, ob man den Klick-Dummy eher als Inspiration versteht, wie man das Dashboard aufbauen könnte (eher von Struktur und Look&Feel, weniger inhaltlich) oder ob man nicht die Visualisierung von Power BI nutzt und statt dessen die Daten in das von lovable erzeugte Cockpit laufen lässt. Ich tendiere aktuell stark zu ersterem!
Das Finale: BI Anbindung und erstes Visualisierung in Power BI
Im letzten Schritt zu sehr fortgeschrittener Stunde habe ich dann Power BI erstmal bei mir als Desktop-Version installiert. Denn wie oben beschrieben: ich hatte mit dem Tool noch keine Erfahrung und es auch noch nicht installiert. Anschließend habe ich dann die SQL-Datenbank mit Power BI verbunden. Das läuft über eine Art Connection Wizzard und die einzige Herausforderung bestand darin, die richtigen Authentifizierungsinformationen parat zu haben (eine Sache, bei der mir ChatGPT ausnahmsweise mal nicht helfen konnte).
Nachdem die Datenbank (alle relevanten Tabellen, das sind im Wesentlichen die oben erstellen Views) importiert wurde (alternativ kann man die Datenbank auch für Echtzeitanwendungen verknüpfen – für meine „Sandbox“ empfand ich den Import als ausreichend), habe ich mit Hilfe von ChatGPT ein paar Kennzahlen erzeugt. Da es schon spät war, habe ich mir auch hier einfach ein paar Vorschläge generieren lassen und diese dann 1:1 in Power BI übernommen. Hierfür musste ich mich auch nicht intensiv mit Power BI beschäftigen, sondern konnte mich hier für alle erforderlichen Klicks von ChatGPT schnell und unkompliziert unboarden lassen.
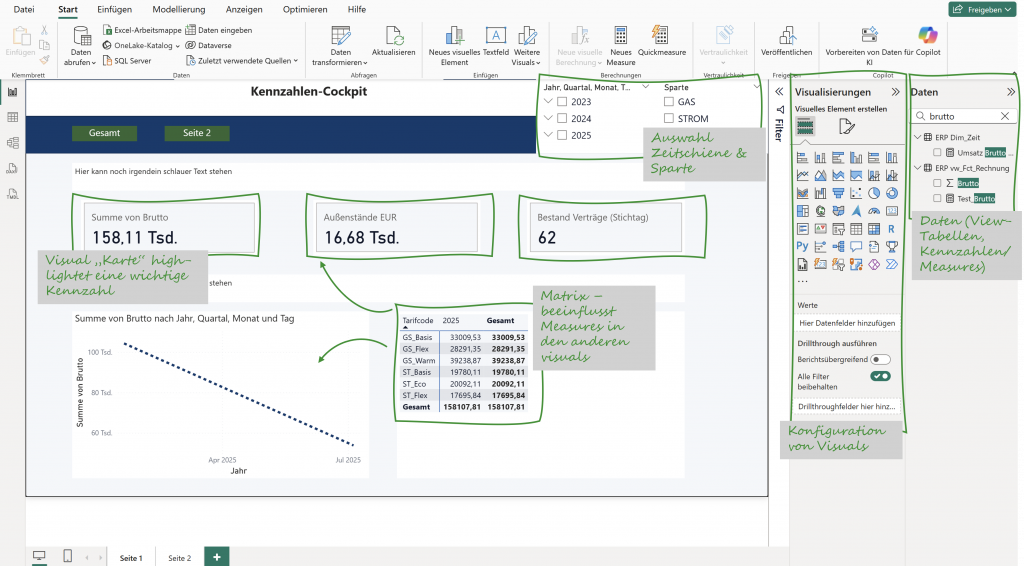
Schlussendlich habe ich noch 4-5 Visuals auf den Report gezogen (per Drag & Drop) und fertig war um kurz vor 3 Uhr nachts das erste Dashboard – mit richtigen Zahlen aus einer falschen Datenbank. Sieht noch nicht so prickelnd aus, lässt sich noch schöner und sinnvoller gestalten. Mehr war aber um die Zeit nicht mehr drin!
Meine Take-aways
An diesem sehr langen Tag habe ich vieles gelernt. Ja, sicherlich ohne die Mega-Tiefe und vielleicht hier und da etwas oberflächlich. Aber hinreichend gut, um es zur Anwendung zu bringen! Die Themen, die ich dabei gestreift habe, sind nicht ohne:
- Tools: SQL, ER-Modellierung, Power BI, ETL-Frameworks.
- Methoden: Datenmodellierung, STAR-Schema, KPI-Design.
- Designprinzipien: Konsistenz, Trennung von Quelle/Transformation/Visualisierung.
Insbesondere habe ich aber einiges über Self-Empowerment mit KI und No-Code-Tools gelernt. Mit etwas Durchhaltevermögen, keine Angst vor „technischer“ ChatGPT-Diskussion ist wirklich einiges drin und man kann sich selbst in sehr kurzer Zeit sehr viele Dinge erschließen. Meine Einschätzung, aber vielleicht liege ich damit auch falsch: es kommt weniger darauf an, dass ich jetzt total treffsicher prompte. Viel vorteilhafter ist eher, dass man eine gewisse analytische Grundbegabung mitbringt, keine Angst vor neuen Tools hat und – macht keinen Spaß – einfach ziemlich umfangreich mitdokumentiert. Denn die nächste ähnlich gelagerte Aufgabenstellung kommt bestimmt.
Die positiven Auswirkungen auf meinen Arbeitsrhythmus würde ich wie folgt zusammenfassen:
- Onboarding: Ich musste mich nicht lange einarbeiten – KI hat mich Schritt für Schritt „an die Hand genommen“.
- Beschleunigung: SQL-Statements, Syntax, Struktur – in Minuten statt Stunden recherchiert.
- Dialog statt Handbuch: Statt in Foren nach Antworten zu suchen, habe ich mit KI im Ping-Pong gearbeitet.
Mag sein, dass ich noch immer in dieser totalen Euphorie des gestrigen Tages stecke. Aber ich kann mich an keine Zeit in meiner über 25-jährigen Laufbahn erinnern, in der ich so schnell, so tief und so selbstständig gelernt habe. Was früher Wochen gedauert hätte, habe ich an einem Tag durchgezogen. Ich denke aber, das lässt sich wiederholen!
Next Step
Spannend wird nun, BI mit Prozess-Automatisierung zu verbinden, z.B. durch Integration von Power Automate Flows. Ich denke hier an die automatisierte Verteilung von Reports oder Dashboard-Links an einen Empfängerkreis, ggf. schon mit einer individualisierten, dynamischen Email. Oder automatische Notifications bei Über- oder Unterschreitung von Warnschwellen.
Neugierig geworden?
Wenn du dich mit Prozessautomatisierung, KI in der Energiewirtschaft oder RAG-gestützten Workflows beschäftigst – melde dich gerne direkt bei mir und wir schauen mal gemeinsam, wie wir in deinem Prozessumfeld die richtigen Hebel bewegen, um dich und dein Team effizienter und produktiver zu machen!